
Artificial intelligence is so hot, as the technical staff of the game industry can not let go, today, we will come together to talk about how artificial intelligence in the game to achieve deep learning technology.
We focus on the wide-ranging problems in the game-based AI based on deep learning and the environments used, such as Atari/ALE, Doom, Minecraft, StarCraft, and racing games. . In addition, we review existing research and identify important challenges that need to be addressed. We are very interested in the method of playing video games (not chess games, such as Go). This article analyzes a variety of games and points out the challenges these games pose to humans and machine players. It must be noted that this article does not cover all AI applications in the game, but focuses on the application of deep learning methods in video games. Deep learning is not the only AI method used in games. Other effective methods are Monte Carlo tree search [12] and evolutionary computation [85], [66].
Deep learning overviewIn this section we outline the deep learning methods used in video games and the hybrid approach of combining multiple methods.
A. Supervised learning
In the supervision of artificial neural networks (ANN), agents learn through samples [56], [86]. The agent needs to make a decision (known to the correct answer), after which the error function is used to determine the difference between the answer provided by the agent and the real answer; this will be used as a loss to update the model. After training on a large data set, the agent should learn the generic model so that it still performs well on the input that has not been seen.
The architecture of these neural networks can be roughly divided into two main categories: feedforward networks and cyclic neural networks (RNN).
B. Unsupervised learning
The goal of unsupervised learning is not to learn the mapping between data and tags, but to discover patterns in the data. These algorithms can learn the feature distribution of a data set, focus on similar data, compress data into necessary features, or create new synthetic data with raw data features.
There are many different techniques in deep learning that allow unsupervised learning. The most important of these is the self-encoder technology, which attempts to output a copy of the self-input copy.
C. Reinforcement learning methods
In reinforcement learning for games, the agent learns to play the game by interacting with the environment. The goal is to learn the strategy, which is what you need to do to achieve the desired state at each step. This situation usually occurs in video games, where the number of actions a player can take at each step is limited, and the order of the actions determines how the player plays.
D. Evolutionary methods
Another method of training neural networks is based on evolutionary algorithms. This method usually refers to neural evolution (neuroevoluTIon, NE), which optimizes network weights and topologies. Compared with gradient-based training methods, the NE method has the advantage of not requiring network differentiation and can be used to supervise learning and reinforce learning problems.
E. Mixed method
Recently, researchers have begun to study a hybrid approach that is suitable for playing video games, combining deep learning methods with other machine learning methods.
These hybrid approaches aim to combine the advantages of both approaches: the deep learning approach can learn directly from high-dimensional raw pixel values, which do not need to rely on a differentiable architecture and perform well in sparsely rewarded games.
A hybrid approach that is significant in board games is AlphaGo [97], which relies on deep neural networks and tree search methods to defeat the world champion in the field of Go.
Game type and research platformThis section outlines popular game types and research platforms (related to deep learning). We briefly outline the features of these games and the challenges that algorithms face when playing games.
A. Arcade game
Classic arcade games were popular in the late 1970s and early 1980s, and have been used as benchmarks for AI over the past decade.
Representative platforms for arcade games are Atari 2600, Nintendo NES, Commodore 64 and ZX Spectrum. Most classic arcade games are characterized by movement in two dimensions, extensive use of graphical logic, conTInuous-TIme progression, and continuous or discrete spatial movement. The challenges of this type of game vary from game to game, but most of these games require quick response and timing. Many games need to prioritize multiple simultaneous events, which requires predicting the behavior or trajectory of other entities in the game. Another common requirement is to go through a maze or other complex environment, such as Pac-Man (a game that appeared in 1980) and a diamond kid (Boulder Dash, a game that appeared in 1984).
The most famous game platform for deep learning methods is the Arcade Learning Environment (ALE) [6]. ALE is built by Atari 2600 simulator Stella and contains 50 Atari 2600 games. The framework extracts game scores, screen pixels of 160 & TImes; 210, and RAM content available for input to the game agent. The platform is the primary environment for the first deep intensive learning papers (using raw pixels as input).
Another classic arcade game platform is the Retro Learning Environment (RLE), which currently includes seven games released to Super Nintendo (SNES) [9]. Many of these games have 3D graphics, and the controller allows for more than 720 combined operations, making the SNES game more complex and lively than the Atari 2600 game, but this environment is currently not as popular as ALE.

Figure 1. Screenshots of several games as a deep learning research platform.
B. Racing game
In a racing game, the player controls a certain car or a character to reach the destination in the shortest time, or travels the farthest distance along the track at a given time. Typically, the game uses a first-person perspective or a player-controlled position behind the vehicle as a viewing angle.
A common challenge in racing games is that the agent needs to use the continuous input after fine-tuning to control the position of the vehicle and adjust the acceleration or braking to get off the track as quickly as possible. This requires at least a short-term planning, one or two turns. Long-term planning is also required if the game also needs to manage other resources, such as energy, destruction or speed. If other vehicles appear on the track, you also need to join the confrontation plan to manage or prevent overtaking.
The environment often used for visual reinforcement learning with 3D images is the open source racing simulator TORCS [121].
C. First Person Shooting Game (FPS)
Recently, the first person shooter game (FPS) has been set as an advanced game environment suitable for visually enhanced learning agents. Compared to the classic arcade game in the ALE benchmark, FPS has 3D images and a stateful portion that is observable, making it a more lively research environment. The usual game perspective is the perspective of the player-controlled character, but a variety of games within the FPS category use an over-the-shoulder perspective. The challenge of this design is fast perception and quick response, especially when you see the enemy and aim quickly. But there are other cognitive challenges, including targeting and moving in complex 3D environments, predicting the movements and locations of multiple enemies; some game modes also require teamwork. If visual input is used in the game, then extracting relevant information from the pixels is also a challenge.
ViZDoom is an FPS platform that allows agents to use the screen buffer as input to play the classic first-person shooter Doom [50]. DeepMind Lab is a 3D navigation and puzzle task platform based on the Quake III Arena engine [2].
D. Open world game
Open world games, such as Minecraft, Grand Theft Auto V, are characterized by non-linearity, a large game world for players to explore, no established goals or a clear internal order, and players have great operations in a given time. free. The key challenge of the agent is to explore the game world and set realistic and meaningful goals. Given that this is a very complex challenge, most studies use these open environments to explore reinforcement learning methods that reuse and migrate learned knowledge to new tasks. Project Malmo is a platform built on the open world game Minecraft that can be used to define a variety of complex problems [43].
E. Real-time strategy game
In this type of game, the player controls multiple characters or units, and the game's goal is to win in a competition or war. The key challenge of real-time strategy games is to develop and execute complex plans involving multiple units. This challenge is usually more difficult than the planning challenge of a classic board game such as chess, because multiple units move at any time, and the effective branching factor is usually very large. Another challenge is to predict the movement of one or more enemies, which have multiple units. Real-time strategy games (RTS) add the challenge of time prioritization to the many challenges of strategic games.
The StarCraft game series is undoubtedly the most studied game in real-time strategy games. The API (BWAPI) of StarCraft and Brood War allows software to communicate with StarCraft during game play, such as extracting state features and performing operations. BWAPI has been widely used in game AI research, but only a few use deep learning. Recently, TorchCraft, a library built on BWAPI, links the scientific computing framework Torch to StarCraft and uses machine learning to study the game [106]. DeepMind and Blizzard (the developer of StarCraft) have developed machine learning APIs to support machine learning in StarCraft II [114]. The API contains several small challenges, although it supports 1v1 game settings. There are two abstract RTS game engines worth mentioning: RTS [77] and ELF [109], which implement multiple features in RTS games.
F. OpenAI Gym & Universe
OpenAI Gym is a large platform that contrasts intensive learning algorithms with separate interfaces, including a range of different environments, including ALE, MuJoCo, Malmo, ViZ-Doom, etc. [11]. OpenAI Universe is an extension of OpenAI Gym that currently has access to more than a thousand Flash games and plans to access more modern video games.
Deep learning method of playing gamesA. Arcade game
The arcade mode learning environment (ALE) has become the main experimental platform for deep reinforcement learning algorithms to learn control strategies directly from the original pixels. This section provides an overview of the major developments in ALE.
The Depth Q Network (DQN) is the first learning algorithm to demonstrate the level of human professional player control in Atari games [70]. The algorithm is tested in seven Atari 2600 games and performs better than previous methods, such as the Sarsa algorithm with feature construction [3] and neuroconvolution [34], and outperforms human expertise in three games.
Deep Loop Q Learning (DRQN) uses the loop layer to extend the DQN architecture before output, which works well for observable games in the state section.
One problem with the Q learning algorithm is that it usually overestimates the action value. Dual DQN based on double Q learning [31] reduces the observed overestimation by learning two value networks, and the two value networks are mutually targeted networks when updated [113].
The network used by Dueling DQN can be divided into two streams after the convolutional layer, estimating the state value V π (s) and the action-advantage Aπ (s, a), respectively, so that Qπ (s, a) = V π (s) + Aπ (s, a) [116]. Dueling DQN is superior to dual DQN and can be connected to prioritized experience playback.
This section also describes the Advantage Actor-Critic (A3C) algorithm, the A3C algorithm using progressive neural networks [88], UNsupervised REinforcement and Auxiliary Learning (UNREAL) algorithms, and Evolution Strategy (ES). Algorithm.
B. Montezuma's Revenge (omitted)
C. Racing games
Chen et al argue that there are two paradigms for vision-based autopilot [15]: (1) direct learning to map images to end-to-end systems of action (behavioral reflection); (2) systems for analyzing sensor data and making informed decisions (Mediated perception).
Policy gradient methods, such as actor-critic [17] and Deterministic Policy Gradient (DPG) [98], can learn strategies in high-dimensional, continuous action spaces. Depth deterministic strategy gradient is a strategy gradient method that implements playback memory and independent target networks, both of which greatly enhance DQN. The depth-deterministic strategy gradient method was used to train TORCS's end-to-end CNN network using images [64].
The aforementioned A3C method was also applied to the racing game TORCS, using only pixels as input [69].
D. First person shooter game
Using Simultaneous Localization and Mapping (SLAM) to obtain position inference and object mapping from the screen and depth buffers, both of which can improve the effectiveness of DQN in the "Destroyer" game [8].
The death tournament champion used the Direct Future Prediction (DFP) method, which is superior to DQN and A3C [18]. The architecture used by DFP has three streams: one for screen pixels, one for low-dimensional evaluation of the current state of the agent, and one for describing the target of the agent, a linear combination of prioritized evaluations.
Navigation in 3D environments is an important skill required for FPS games and has been extensively studied. The CNN+LSTM network uses A3C training, and the A3C is extended with additional output that predicts pixel depth and loop closure, showing a significant improvement [68].
The Intrinsic Curiosity Module (ICM) consists of multiple neural networks that calculate intrinsic rewards based on the inability of the agent to predict the outcome of the action in each time step.
E. Open world game
The Hierarchical Deep Reinforcement Learning Network (H-DRLN) architecture implements a lifelong learning framework that migrates knowledge, such as navigation, item collection, and layout tasks, in a simple task of the game My World. ]. H-DRLN uses a variant strategy oscillation [87] to preserve the knowledge gained and encapsulate it into the entire network.
F. Real-time strategy game
The environment for real-time strategy (RTS) games is more complex, and players must synchronize multiple agents in real-time on partially observable maps.
There are several methods for real-time strategy:
Independent Q Learning (IQL) simplifies multi-agent reinforcement learning problems. Agents learn a strategy that can control units independently and treat other agents as part of the environment [107].
The Multi-Agent Bidirectional Coordination Network (BiCNet) implements a vectorized actor-critic framework based on bidirectional RNN, where one dimension is applied to each agent and its output is a series of operations [82].
Counterfactual multi-agent (COMA) strategy gradient is an actor-critic method with a centralized critic and multiple decentralized actors, which are solved by the counterfactual baseline calculated by the critic network. The problem of intelligent body reliability distribution [21].
G. Physics Games (omitted)
H. Text-based games
The state and operations in this type of game are presented in text form and are a special type of video game. Researchers have designed a network architecture called LSTM-DQN [74] to play such games. Using the LSTM network, you can convert text from a world state to a vector representation, evaluating the Q values ​​of all possible state-action pairs.
Open challengeDeep learning, especially deep intensive learning methods, has achieved remarkable results in video games, but there are still a number of important open challenges. We will outline this in this section.
  A. General video games
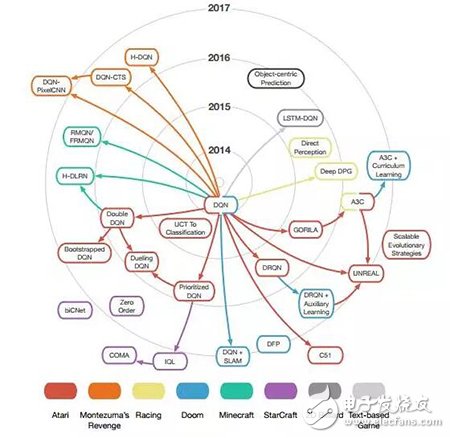
Figure 3. Impact of deep learning techniques discussed in this article
Each node in Figure 3 represents an algorithm, the color represents the game benchmark, the distance from the center represents the publication time of the original paper on arXiv, the arrow represents the relationship between the technologies, and each node points to all nodes that use or modify the technology. . The influences not discussed in this paper are not shown in the figure.
B. Sparse reward game
C. Multi-agent learning
D. Computing resources
E. Application of deep learning methods in the game industry
F. Game development interactive tool
G. Creating new video games
H. Lifelong adaptability
I. Play games similar to humans
J. Performance level adjustable agent
K. Learning model of the game
L. Handling large decision spaces
in conclusionThis paper reviews the deep learning methods applied to video games. The types of video games involved include: arcade games, racing games, first-person shooters, open world games, real-time strategy games, physics games, and text-based games. game. Most of the work involved is end-to-end model-free deep reinforcement learning, in which convolutional neural networks can learn to play games directly from the original pixels through game interaction. Some studies have also demonstrated the use of supervised learning to learn from the game log, allowing the agent to interact with itself in the game environment. For some simple games, such as many arcade games, many of the methods discussed in this article have outperformed humans, and more complex games face many open challenges.
China leading manufacturers and suppliers of SMA Cable Mount Connectors,SMA Bulkhead Mount Connectors, and we are specialize in SMA Flange Mount Connectors,SMA PCB Mount Connectors, etc.
SMA Cable Mount Connectors,SMA Bulkhead Mount Connectors,SMA Flange Mount Connectors,SMA PCB Mount Connectors
Xi'an KNT Scien-tech Co., Ltd , https://www.honorconnector.com