
In this article, we describe an audio data set recently released by Google that is used to help train and evaluate spoken word recognition systems. Discussed why the task is an interesting challenge, and why it requires a specialized data set that differs from the traditional data set used for automatic speech recognition of complete sentences.
We propose a reproducible and comparable measure of accuracy for this task. Describes how data is collected and verified, what it contains, and its previous versions and attributes. The conclusion was reached by reporting the baseline results of the model trained on this data set.
In general, speech recognition research has traditionally required the resources of large institutions such as universities or corporations to conduct research. People working in these institutions can often reach agreements with organizations such as the Linguistic Data Consortium to freely access and use academic data sets or proprietary business data.
With the maturity of voice technology, the number of people who want to train and evaluate the recognition model has been more than just these traditional organizational groups, but the availability of data sets has not been expanded. As shown by similar collections in ImageNet and computer vision, broadening access to datasets can encourage cross-organizational collaboration and enable comparisons between different approaches to help the entire field move forward.
Speech Commands dataset is an attempt to build a standard training and assessment data set for a simple type of speech recognition task. Its main goal is to provide a way to build and test small models that can use as few false positives as possible from background noise or unrelated speech from a set of 10 or fewer target words. In the detection of the use of a single word, this task is often referred to as keyword recognition.
In order to cover a wider range of researchers and developers, this data set has been released under the Creative Commons 4.0 license. This allows the data set to be easily incorporated into tutorials and other scripts that can be downloaded and used without any user intervention (for example, registering on a website or sending an e-mail to an administrator for permission). This license is also well-known in the business environment, so it is usually handled quickly by the legal team when approval is required.
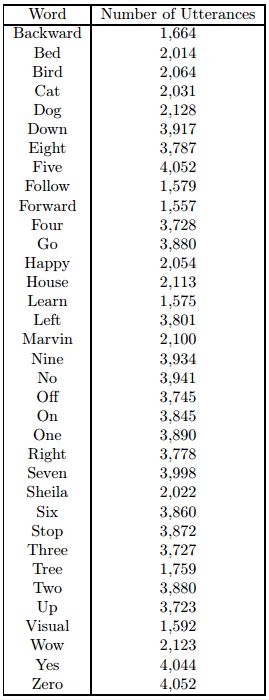
Figure 1: The number of records for each word in the dataset
Related research
Mozilla's Common Voice dataset has more than 500 hours of voice for 20,000 different people and can be used under a "Creative Commons" Zero license (similar to a public domain). This license makes it very easy to build it. It is aligned by sentences and created by volunteers reading the requested phrase through a web application.
LibriSpeech is a 1000-hour reading English speech set released under the Creative Commons 4.0 license and stored using a widely supported open source FLAC encoder. Its tags are only aligned at the sentence level and therefore lack word-level alignment information. This makes it more suitable for automatic speech recognition than keyword recognition.
TIDIGITS contains 25,000 digit sequences recorded by 300 different speakers, recorded by paid participants in a quiet room. This data set can only be used under a commercial license from the Linguistic Data Alliance and is stored in the NIST SPHERE file format, which has proven to be difficult to decode using modern software. Our initial experiment on keyword recognition was performed using this data set.
The CHiME-5 has 50 hours of voice recordings recorded in people's homes, stored as 16 KHz WAV files, and can be used with a limited license. It is aligned at the sentence level.
Many speech interfaces rely on keyword recognition to initiate interactions. For example, you might say "Hey Google" or "Hey Siri" to start inquiring or ordering your phone. Once the device knows that you want to interact, it can send the audio to the Web service to run a model that is limited only by business considerations because it can run on servers whose resources are controlled by the cloud service provider. Although the initial detection of the start of the interaction is intended to be run as a cloud-based service, it is impractical because it needs to always send audio data from all devices over the network. This maintenance costs will be very high and will increase the privacy risk of the technology.
Instead, most voice interfaces run identity modules locally on mobile phones or other devices. This kind of continuous monitoring of audio input from the microphone does not send data to the server over the Internet, but they run a model that listens to the trigger phrase needed. Once the possible trigger signal is heard, audio transmission to the Web service starts. Because the native model runs on hardware that is not controlled by the Web service provider, the device model must respect hard resource limitations. The most obvious of these is that usually the mobile processor has a much lower total computing power than most servers. Therefore, in order to achieve an interactive response and run in near real-time, the calculation of the device model must be less computationally intensive. Effective cloud computing.
What's more ingenious is that the battery life of mobile devices is limited, and any devices that continue to run need to be very energy-efficient, otherwise users will find that the power consumption of the devices is too fast. This consideration does not apply to plug-in home appliances, but there is a limit to how much heat these appliances can dissipate, which limits the amount of energy available to the local model and is encouraged by programs such as Energy Star. Reduce its overall power consumption as much as possible. The last thing to consider is that the user expects the device to be able to respond quickly, and the network delay may vary greatly due to the environment. Therefore, even if the overall response of the server is delayed, the initial confirmation received by some commands is very good for a good experience. important.
These constraints mean that the task of keyword recognition is completely different from the speech recognition performed on the server once the interaction is discovered:
The key recognition model must be smaller and less involved in calculations.
They need to operate in a very energy-efficient manner.
Most of their inputs are silent or background noises, not words, so false alarms must be minimized.
Most speech input is independent of the speech interface, so the model should not trigger any speech.
The important unit of recognition is a single word or phrase, not the entire sentence.
These differences mean that the training and assessment process between keyword recognition and general speech recognition models within the device is completely different. There are some promising data sets that can support common voice tasks, such as Mozilla's universal voice, but they are not easily applicable to keyword recognition.
This voice command data set is designed to meet the special needs of models on building and testing devices, allowing model authors to demonstrate the accuracy of their architecture using metrics that are comparable to other models, and provide teams with a simple way to The same data is trained to reproduce the benchmark model. It is hoped that this will accelerate progress and collaboration and increase the overall quality of the available models.
The second important audience is the hardware manufacturer. By using publicly available tasks that closely reflect product requirements, chip vendors can demonstrate the accuracy and energy usage of their products in a way that is easily comparable to potential buyers. This increased transparency should result in hardware that better meets product requirements. These models should also provide clear specifications that hardware engineers can use to optimize their chips, and may propose model changes to provide more efficient implementations. This collaborative design between machine learning and hardware can be a virtuous cycle that increases the flow of useful information between various domains, and this helps both parties.

Figure 2: Top-One accuracy assessment results using different training data
Version 1 of this data set was released on August 3, 2017 and contains 64,727 statements from 1,881 speakers. The V1 training data was used to train the default convolution model from the TensorFlow tutorial (small size keyword recognition based on the convolutional neural network). When evaluating the V1 test set, the TopOne score was 85.4%. Using the dataset version 2 recorded in this paper to train the same model, a model was generated which scored 88.2% in the Top-One training set extracted from the V2 data. Training was performed on V2 data, but the model evaluated for the V1 test set yielded a Top-One score of 89.7%, indicating that the V2 training data was significantly more accurate than V1. Figure 2 shows the complete result.
In summary, this voice command data set is very useful for training and evaluating multiple models, while the second version shows improved results compared to the equivalent test data of the original data.
Switch vape to Voom Iris 600 puff 20mg mint disposable device 2ml tank with 320mah rechargeable battery stylish and sleek design with double shell mould available in 14 crafted cool e-cig flavours.
Blueberry Ice vape, 2ml Prefilled Pod, 600 Puffs, 500mAh Battery. If you're looking for something delectable, Voom has you covered with this wonderful new Blueberry Ice Puff Bar flavour. Voom has produced a disposable vape that flawlessly blends beautiful flavours such as ripe blueberry notes that will tantalise your tastes, which are then mixed with a refreshing ice impact to offer a pleasantly fruity vape pleasure.
The Voom Iris Mini Disposable Vape has a sleek, cool, simple design with a clear plastic outer shell over the mouthpiece. Looks don't have to be complex to be eye-catching, and this device doesn't fall short in that department. Enjoy up to 600 puffs per device.
Mint: We've all had a mint, right? Refreshing and breath-fixing all at once. This is like that, but without any of the social benefits of a breath mint.

VOOM Iris Mini,VOOM VAPE,600puffs vape,Voom Iris 600 puff,VOOM Iris Mini Vape
Shenzhen Kester Technology Co., Ltd , https://www.kesterpuff.com