
Recently, Yann LeCun et al. published a paper on segmentation prediction for future examples. The paper proposes a predictive model that predicts future instance segmentation by predicting convolutional features. The algorithm has the following major advantages:
Can handle unfixed model output sizes, such as object detection and instance segmentation;
It is not necessary to use labeled video sequences for training, and an intermediate CNN feature map can be calculated directly from untagged data.
Supports models that generate multiple scene interpretations, such as surface normals, object bounding boxes, and human part labels, without the need to design suitable encoder and loss functions for these tasks.

Introduction
Predicting future events is an important prerequisite for achieving smart behavior, and video forecasting is one of the tasks. Recent studies have shown that when semantically segmenting future frames, the prediction at the semantic level is more efficient than predicting RGB frames first and then segmenting them. This article considers one of the more challenging issues in future instance segmentation—subdivide individual objects. In order to deal with different numbers of output tags in each image, we developed a predictive model in the fixed-size convolutional feature space of the Mask R-CNN instance segmentation model.
We apply the "detection head" of the Mask R-CNN framework to the prediction features to generate instance splits of future frames. Experiments show that compared with the baseline based on optical flow, the algorithm has a significant improvement in performance.

Figure 1: Predicting the next 0.5 seconds. Optical flow baseline (a) and the segmentation comparison of the algorithm (b) of this paper. Comparing the semantic segmentation of the algorithm (c) from the literature [8] and the semantic segmentation algorithm (d) of this article. Instance modeling significantly increases the accuracy of individual pedestrian segmentation.
Our contribution is as follows:
Introducing future examples to predict this new task is semantically more informative than previously anticipated.
Self-supervised algorithms based on the characteristics of high-dimensional convolutional neural networks for predicting future frames support multiple expected recognition tasks.
The experimental results show that our feature learning algorithm is improved compared to the strong light stream baseline.
Predict the characteristics of future instance segmentation
This section briefly reviews the Mask R-CNN framework instance segmentation framework and then describes how to use the framework for anticipated recognition by predicting the internal CNN features of future frames.
Masking with Mask R-CNN
The Mask R-CNN model consists of three main phases. First, a high-level feature map is extracted using a CNN backbone framework structure. Second, the Candidate Area Generating Network (RPN) uses these features to generate a Region of Interest (ROI) in the form of instance bounding box coordinates. Candidate bounding boxes are used as input to the region of interest layer, and a fixed-size representation (regardless of size) is obtained for each bounding box by inserting advanced features in each bounding box. The features of each region of interest are input to the detection branch and produce precise bounding box coordinates, category prediction, and a fixed binary mask for the prediction category. Finally, the mask is inserted into the image resolution within the predicted bounding box and reported as an instance partition of the predictive class.
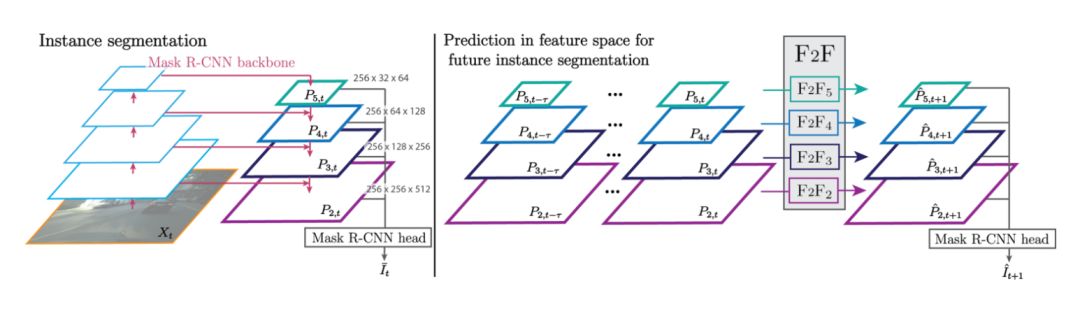
Figure 2: Left-up, top-down feature sampling combines the bottom-up features of the same resolution bar, resulting in features in the backbone framework of the FPN (feature pyramid network) algorithm. Right, in order to get future instance partitions, we extract FPN features from t-Ï„ to t frames and predict the FPN features of t + 1 frames.
Predictive convolution features
Features that are at different FPN levels are trained and used as inputs for shared "detection heads." However, because the resolution changes at different levels, the "spatial-time" dynamics on each layer will be different. Therefore, we propose a multi-scale algorithm that uses separate networks for each stage to predict. Each level of network is trained to work completely independent of each other. For each level, we focus on the characteristics of the feature dimension input sequence.
Experimental evaluation
We used the Cityscapes dataset. The data was taken from the video of the urban environment recorded during the driving of the car. Each video segment was 1.8 seconds long and was divided into 2,975 training sets, 500 validation sets, and 1,525 test sets.
We use the pre-trained Mask R-CNN model on the MS-COCO dataset and fine-tune it in an end-to-end fashion on the Cityscapes dataset.
Future Example Segmentation: Table 1 is an example segmentation result of the Future Feature Prediction Algorithm (F2F) and compares it with the performance of Oracle, Copy, and optical flow baselines. As can be seen from the table, the F2F algorithm works best, which is more than 74% better than the best medium-term baseline.
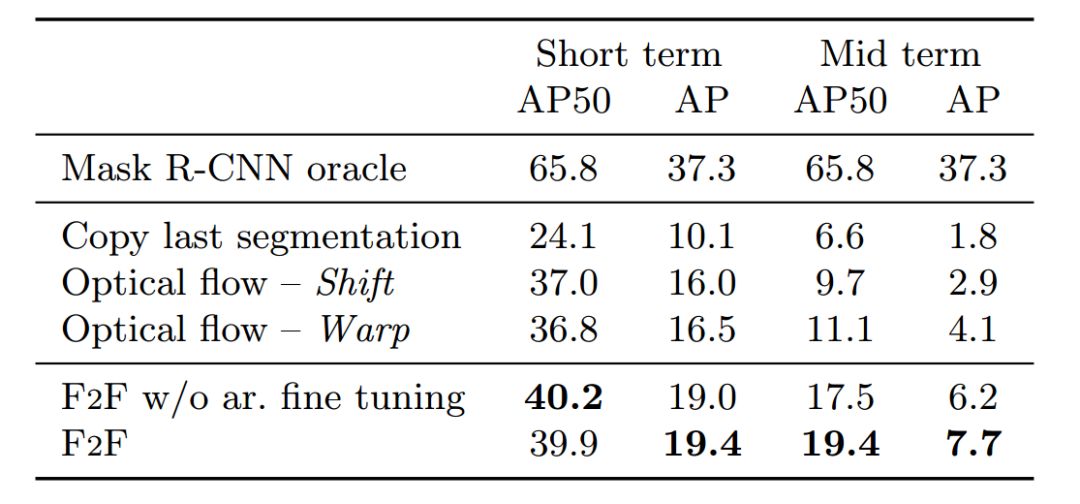
Table 1: Accuracy of instance segmentation on Cityscapes val. dataset
Future Semantic Segmentation: We have found that the F2F algorithm has significantly improved IoU over all short-term segmentation methods, ranking first in terms of 61.2%.
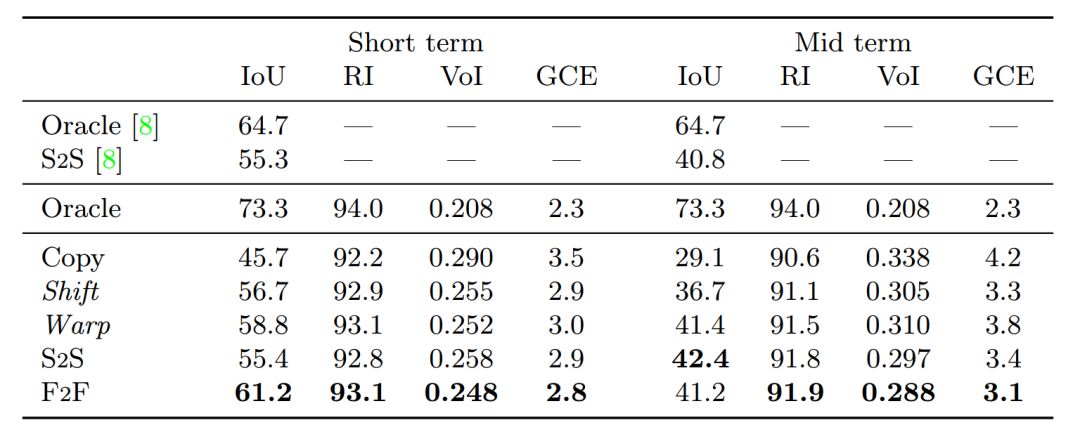
Table 2: Short-term and mid-term semantic segmentation of moving objects of different algorithms on the Cityscapes val. dataset (Class 8).
Figure 4 shows that compared with the Warp baseline, the F2F algorithm can be better aligned with the actual layout of the object, which indicates that the algorithm has learned to dynamically model the scene and object, and the effect is better than the baseline. As expected, the predicted mask is also more accurate than those of the S2S algorithm.

Figure 4: Medium-term predictions for the three series (in the next 0.5 seconds).
With the example shown in Figure 5, we can better understand why the difference between F2F and Warp baselines is much smaller than the case segmentation metrics in semantic segmentation metrics.

Figure 5: Example and semantic segmentation of medium-term predictions obtained with the Warp baseline and F2F model. Inaccurate instance segmentation results in an exact semantic segmentation. See the orange rectangle highlights in the picture.
Failure case discussion
In the first example of Fig. 6(a), no detection was made because all previous models believed that the white car was completely blocked by another car. This is an inevitable situation, unless the object is visible in earlier frames. In this case, long-term memory mechanisms may avoid unnecessary errors.
In Figure 6(b), truck and pedestrian prediction masks are not consistent in shape and position. With a clearly modeled occlusion mechanism, a more consistent prediction may be obtained.
Finally, because of the ambiguity of the object itself, some movements and shape transformations are difficult to predict accurately, as in the leg of the pedestrian in Figure 6(c). For this case, there is a high degree of uncertainty in the exact pose.

ZGAR Accessories
ZGAR electronic cigarette uses high-tech R&D, food grade disposable pod device and high-quality raw material. All package designs are Original IP. Our designer team is from Hong Kong. We have very high requirements for product quality, flavors taste and packaging design. The E-liquid is imported, materials are food grade, and assembly plant is medical-grade dust-free workshops.
Our products include disposable e-cigarettes, rechargeable e-cigarettes, rechargreable disposable vape pen, and various of flavors of cigarette cartridges. From 600puffs to 5000puffs, ZGAR bar Disposable offer high-tech R&D, E-cigarette improves battery capacity, We offer various of flavors and support customization. And printing designs can be customized. We have our own professional team and competitive quotations for any OEM or ODM works.
We supply OEM rechargeable disposable vape pen,OEM disposable electronic cigarette,ODM disposable vape pen,ODM disposable electronic cigarette,OEM/ODM vape pen e-cigarette,OEM/ODM atomizer device.

ZGAR Accessories Disposable Pod Vape,ZGAR Accessories Disposable Vape Pen,ZGAR Accessories,ZGAR Accessories Electronic Cigarette,ZGAR Accessories OEM vape pen,ZGAR Accessories OEM electronic cigarette.
ZGAR INTERNATIONAL(HK)CO., LIMITED , https://www.zgarvapepen.com