
Posted by: Aseem Agarwala, Head of Content Team, Researcher, Clips
In my opinion, photography is the importance of recognizing an event in an instant, while recording its appearance through a precise combination of forms.
- Henri Cartier-Bresson
In the past few years, artificial intelligence experienced a similar explosion in the Cambrian era. With deep learning methods, computer vision algorithms have been able to identify many elements of good quality photos, including people, smiles, pets, sunsets, and famous landmarks. and many more. However, despite a series of recent advances, automatic photography is still a difficult problem to overcome. Can the camera automatically capture extraordinary moments?
Some time ago, we released Google Clips, a brand new hands-free camera that automatically captures the fun of life. We have followed three important principles when designing Google Clips:
We want all calculations to be performed on the device side. In addition to extending battery life and reducing latency, device-side processing also means that any clips will not leave the device unless saved or shared. This is an important privacy measure.
We want the device to be able to shoot short videos instead of single photos. Because the action can better record the momentary form, leaving a more realistic memory, and shooting video for an important moment is often easier than capturing a perfect moment instantly.
We want to focus on capturing the true moments of people and pets, rather than focusing on capturing more abstract and subjective issues of artistic images. That is, we did not try to teach Clips to think about composition, color balance, and lighting, but instead focus on how to select moments that include people and animals for interesting activities.
Learn to identify extraordinary moments
How to train algorithms to identify interesting moments? As with most machine learning problems, we start with data sets. First imagine various application scenarios of Clips, and then create a data set consisting of thousands of videos. At the same time, we also ensure that these data sets cover a wide range of race, gender, and age groups. Then we hired professional photographers and video editors to scrutinize the video and select the best short video clip. These pre-processing methods provide examples of our algorithms that can be imitated. However, training an algorithm based solely on the subjective choice of professionals is not easy. We need a smooth label gradient to teach the algorithm to recognize the quality of content (from "perfect" to "worse").
In order to solve this problem, we have adopted another data collection method with the goal of creating a continuous quality score for the entire video. We edited each video into short clips (similar to what Clips captured), then randomly selected clip pairs and asked human graders to select their favorite clips.
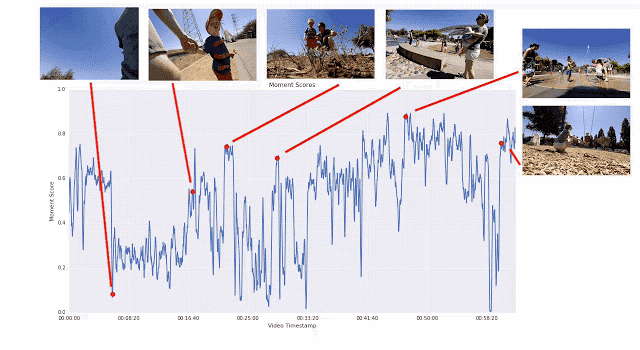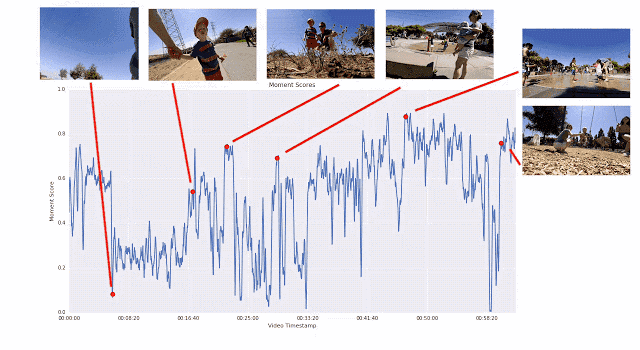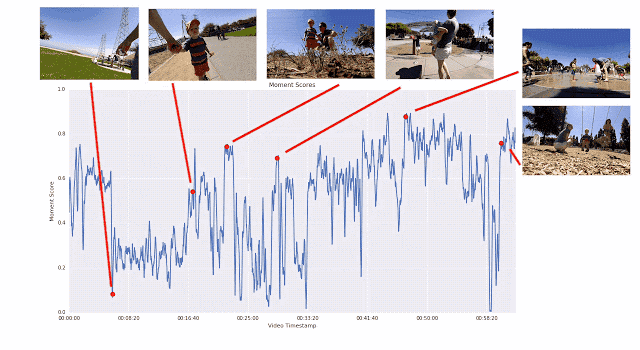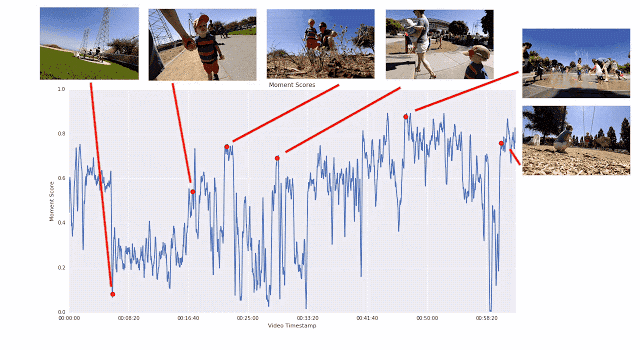
The use of this pairwise comparison method, rather than allowing the rater to directly rate the video, is because it is easier to choose the best than to give a specific score. We found that the scorers had very consistent conclusions when comparing in pairs, and there was a big difference in direct scores. If we provide enough short films for any given video, we can calculate the continuous quality score for the entire video. Through this process, we collected more than 50 million pairs of comparative short films from more than 1,000 videos. If you rely solely on manpower, this job will be extremely hard.
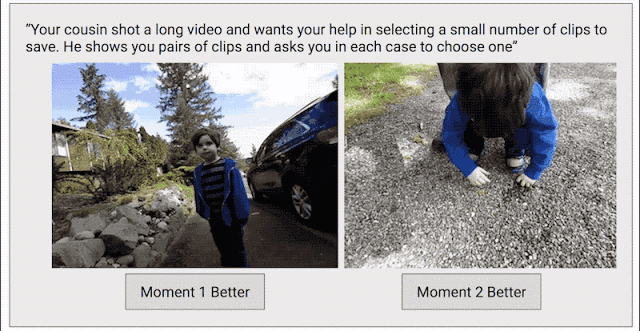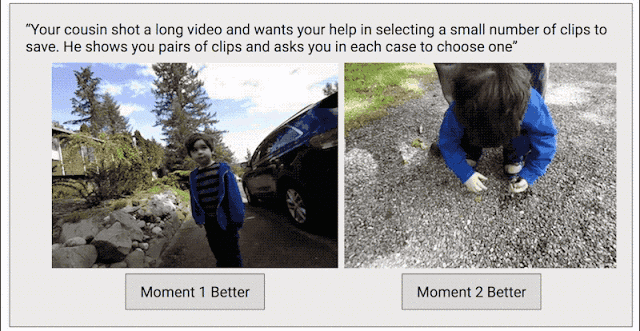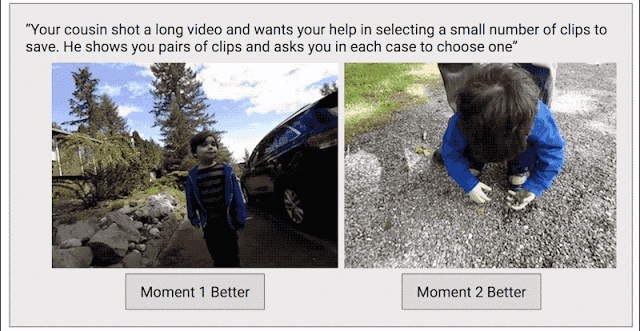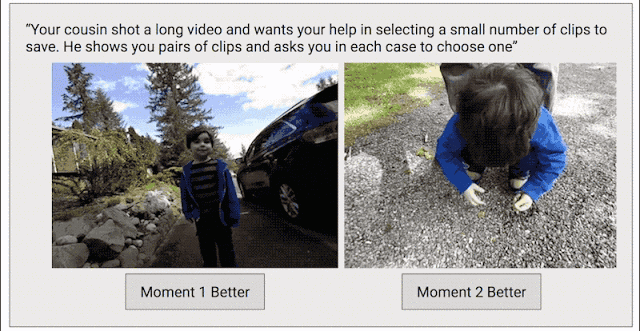
Training Clips Quality Model
After mastering the quality score training data, the next step is to train a neural network model to evaluate the quality of any photograph captured by the device. We first made a basic assumption that understanding the contents of photos (such as people, dogs, trees, etc.) helps determine "interestingness." If this assumption is correct, then we can learn a function that predicts its quality score by identifying the content of the photograph (as described above, the score is based on the results of human comparative evaluation).
To determine content labels in training data, we used Google Machine Learning technology that supports Google Image Search and Google Photos, which identifies more than 27,000 different tags that describe objects, concepts, and actions. Of course we don't need all the tags and we can't calculate all the tags on the device, so professional photographers are asked to choose hundreds of tags that they think are most relevant to the “funny†of the predicted photos. We also added a tag that has the highest relevance to the grader Quality Score.
With this subset of tags, we need to design a compact and efficient model that predicts the labeling of any given image on the device side under conditions of limited power and heat. This work poses a big problem because the deep learning technology supported by computer vision usually requires a powerful desktop GPU, and the algorithms running on mobile devices lag far behind the latest technologies on the desktop or cloud. To perform this training on the device-side model, we first collected a large number of photos and then used Google's powerful server-based recognition model again to predict the confidence of each of these "fun" tags. We then trained a MobileNet Image Content Model (ICM) to mimic the prediction of a server-based model. This compact model can identify the most interesting elements in a photo while ignoring irrelevant content.
The last step is to use the 50 million-long contrast short piece as training data to predict the quality score of the input photo using the ICM-predicted photo content. Scores are calculated using a piecemeal linear regression model that converts the ICM output to a frame quality score. The average of the frame quality scores in the video clip is the instantaneous score. Given a comparably short slice, the instantaneous score of the human-preferred video segment calculated by our model should be higher. The purpose of the training model is to make its prediction as consistent as possible with humans.
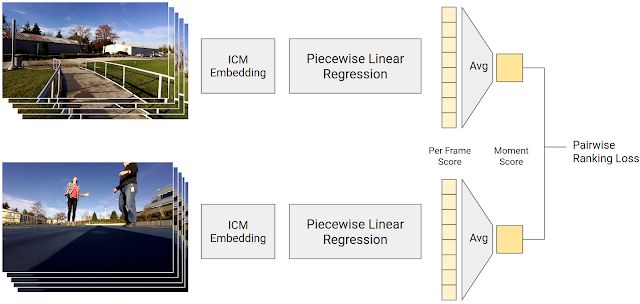
An illustration of the training process that generates the frame quality score. The segment-by-segment linear regression model maps the ICM embedding to the frame quality score. The average score of all the frame quality scores in the video clip is the instantaneous score. Instant scores for human-preferred video clips should be higher.
Through this process, we trained a model that perfectly integrates Google's image recognition technology with the intelligence of human graders (50 million comments on the content's interestingness).
This data-based score has done a good job of identifying interesting (and boring) moments, and we have added some additional bases to it, adding some rewards for the overall quality score of the events we want Clips to capture. Including the face (especially the "familiar" face that often appears), smiles, and pets. In the latest version, we have added incentives for certain activities that customers particularly want to capture, such as hugging, kissing, jumping and dancing. To identify these activities, you need to extend the ICM model.
Photo control
Based on this powerful scene "funny" prediction model, the Clips camera can determine which moments need real-time capture. Its camera control algorithm follows the following three principles:
Pay attention to power consumption and heat: We hope the battery of the Clips can last for about three hours, and at the same time do not want the equipment to overheat, so the equipment cannot run at full speed. Clips spends most of their time in a low-power mode that shoots one frame per second. If the quality of this frame exceeds the threshold set according to the Clips recent shot, it will enter a high power consumption mode and shoot at 15 fps. Clips then saves the clip when it encounters the first mass peak.
Avoid Redundancy: We don't want Clips to capture all the moments at once and ignore the rest. Therefore, our algorithm aggregates these moments into visually similar groups and limits the number of clips in each cluster.
The benefits of hindsight: It is obviously much easier to select the best clip after viewing all the shots. As a result, Clips captures more of the moment than expected. When a clip is to be transferred to a mobile phone, the Clips device takes a second to view its capture and only transmits the best and least redundant content.
Machine learning fairness
In addition to ensuring that the video dataset demonstrates the diversity of population groups, we have also built a number of tests to evaluate the fairness of our algorithm. We create controlled datasets by uniformly sampling from different genders and skin tones, while keeping variables such as content type, duration, and environmental conditions constant. We then use this dataset to test whether the algorithm has similar performance when applied to other groups. In order to help detect any fairness regression that may occur when promoting an instantaneous quality model, we have added fairness tests to automated systems. Any changes made to the software must be tested and the requirements must be passed. However, it should be noted that this method does not ensure fairness because we cannot test every possible scenario and outcome. However, the fairness of implementing machine learning algorithms is a long way to go and can not be achieved overnight, and these tests will help to promote the ultimate realization of the goal.
in conclusion
Most machine learning algorithms are designed around objective characterization, for example, to determine if a cat is in a photo. In our use case, our goal is to capture a more elusive and more subjective characteristic, that is, to determine whether personal photos are interesting. Therefore, we combine the objective and semantic content of photographs with subjective human preferences to implement artificial intelligence in Google Clips. In addition, the design goal of Clips is to work with people instead of working autonomously; in order to obtain good shooting results, the shooter must still have a sense of framing and ensure that the camera is aimed at interesting shooting content. We are gratified by the excellent performance of Google Clips and look forward to continuing to improve the algorithm to capture the "perfect" moment!
Acknowledgements
The algorithm described in this article was conceived and implemented by many Google engineers, researchers, and others. Image produced by Lior Shapira. Thanks also to Lior and Juston Payne for providing video content.
A new rule from the Drug Enforcement Administration (DEA) threatens to upend the American hemp industry, and could even result in criminal prosecutions for manufacturers of CBD and delta-8 THC products.
The DEA says the [interim final rule," issued Aug. 20, is simply a matter of adjusting its own regulations to account for changes to the Controlled Substances Act that were mandated by the 2018 Farm Bill (or Agricultural Improvement Act) that legalized hemp and CBD production. The new rule [merely conforms DEA`s regulations to the statutory amendments to the CSA that have already taken effect," says the agency. The new rule doesn`t break any ground, according to the DEA.
But many experts on cannabis and hemp law say the DEA rule creates a potential pathway the law enforcement agency could use to prosecute hemp processors and producers of CBD (cannabidiol) and delta-8 THC (or Δ8THC) products. There are two issues: partially processed CBD, and [synthetically derived" delta-8 THC.
Cbd Pod System Oem,Cbd Vape Pod Oem,Best Cbd Pod System,Cbd Pod System
Shenzhen MASON VAP Technology Co., Ltd. , https://www.e-cigarettefactory.com