
The Recurrent Neural Network (RNN) is the mainstream architecture for natural language modeling. Typically, the RNN reads the input tokens in sequence and outputs a distributed representation of each token. By using the same function to cyclically update the hidden state, the computational cost of the RNN will remain the same. Although this feature is common for some applications, not all tokens are equally important in language processing, and the key is to learn to choose. For example, in a quiz, only a large number of important parts are calculated, and an unrelated part is allocated a small number of calculations.
Although methods such as Attention Model and LSTM improve computational efficiency or select important tasks, they do not perform well enough. In this paper, the researchers put forward the concept of "Skim-RNN", which uses a small amount of time for fast reading without affecting the reader's main goal.
The composition of Skim-RNN
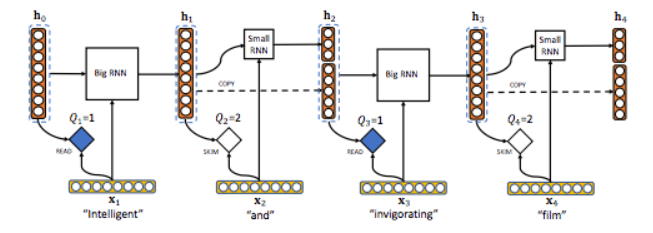
Inspired by the principle of human fast reading, the structure of Skim-RNN consists of two RNN models: a larger default RNN model d and a smaller RNN model d'. d and d' are user-defined hyperparameters, and d'<< d.
If the current token is important, Skim-RNN will use a large RNN; if it is not important, it will switch to a small RNN. Since small RNNs require fewer floating-point operations than large RNNs, this model is faster or even better than using large RNNs alone.
Reasoning process
In each step t, Skim-RNN outputs the new state ht by taking the input Xt ∈ Rd and the previous hidden state ht-1 ∈ Rd as its parameters. k represents the number of times a harddecision is made at each step. In Skim-RNN, whether it is full reading or skipping, k=2.
The researchers used a number of random variables Qt to model the decision process for selecting the probability distribution Pt. Pt is expressed as:
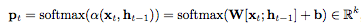
Here, W∈Rk×2d, b∈Rk.
Next we define the random variable Qt by sampling Qt from the probability distribution Pt:
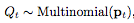
If Qt=1, then the model is the same as the standard RNN model. If Qt = 2, then the model uses a smaller RNN model to get a smaller hidden state. which is:
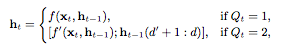
Where f is the full RNN with d output, and f' is the small RNN with d' output, d'<< d.
Experimental result
The researchers tested Skim-RNN on seven sets of datasets, including classification tests and quiz questions, to verify the accuracy of the model and the floating-point reduction rate (Flop-R).
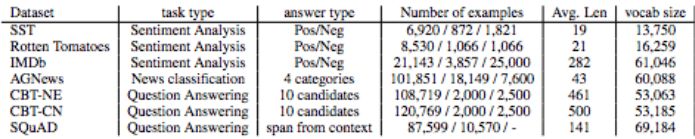
Text Categorization
In this task, the input is a sequence of words, and the output is a vector of classification probabilities. Finally, the table below shows the accuracy and computational cost of the Skim-RNN model compared to LSTM and LSTM-Jump.

This article uses SST, Rotten Tomato, IMDB and AGnews as examples to classify this article and compare it on standard LSTM, Skim-RNN, LSTM-Jump and the most advanced model (SOTA).
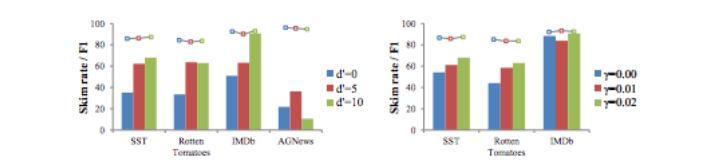
The effect of changing the size of the smaller hidden state, and the effect of the parameter γ on accuracy and computational cost (default d=100, d'=10, γ=0.02)
The following figure is an example of the IMDB data set. The parameters of Skim-RNN are: d=200, d'=10, γ=0.01, and the probability of correctly classifying this paragraph is 92%.

The black word is skipped (using the small LSTM model, d'=10), and the blue word is read (using the larger LSTM model, d=200)
As expected, the model ignores words that are not important, such as prepositions, and notices very important words such as "like", "terrible", and "disgusting".
Answer question
The purpose of this task is to find the location of the answer in a given paragraph. To test the accuracy of the Skim-RNN, the researchers created two different models: LSTM+Attention and BiDAF. The result is as follows:
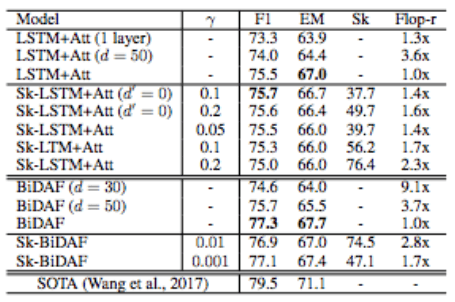
The F1 and EM values ​​indicate the accuracy of the Skim-RNN. It was finally found that the F1 score of the skimming model was the same or even higher than the model without the default non-skimming, and the computational cost was less (more than 1.4 times).
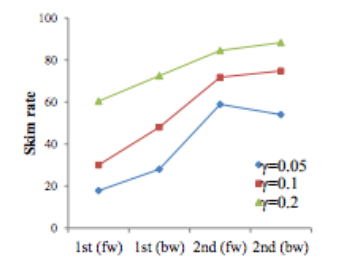
In the LSTM+ attention model, the LSTM speed rate of different layers changes with the change of γ.

F1 score for the LSTM+ Attention Model. The higher the computational cost, the better the model performs. At the same cost of calculation, Skim LSTM (red) performs better than standard LSTM (blue). In addition, the F1 score of Skim-LSTM is more stable under different parameters and calculation costs.
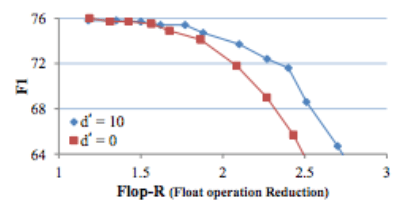
The relationship between F1 score and Flop-R
The following picture is an example of a model answering question. The question is: What is the largest construction project? (correct answer: megaprojects)
The answer given by the model: megaprojects.
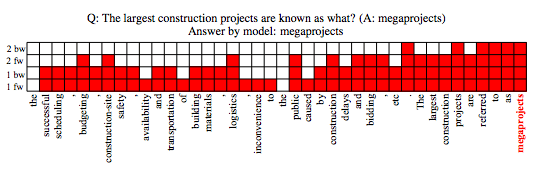
Red for reading, white for skipping
operation hours
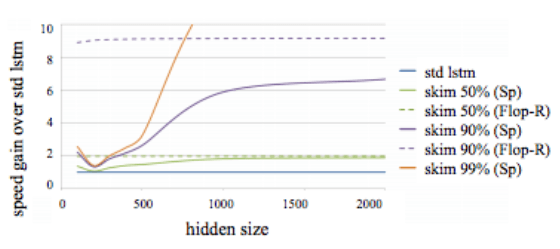
The figure above shows that the hidden state of the relative speed gain of the Skim-LSTM has different sizes and speed rates compared to the standard LSTM. In the process, the researchers used NumPy and made inferences on a single thread of the CPU.
It can be seen that the difference between the actual gain (solid line) and the theoretical gain (dashed line) cannot be avoided. As the hidden state increases, this gap will decrease. So for a bigger hidden state, Skim-RNN will perform better.
Conclusion
This study shows that the new cyclic neural network Skim-RNN can decide whether to use a large RNN or a small RNN depending on the importance of the input, and the calculation cost is lower than that of the RNN. The accuracy is similar or even more accurate than the standard LSTM and LSTM-Jump. it is good. Since Skim-RNN has the same input and output interfaces as RNN, it is easy to replace RNN in existing applications.
Therefore, this kind of work is suitable for applications that require a higher hidden state, such as understanding video, and can also use small RNN to do different levels of skimming.
2-Piece Fixing Ties with Pipe Clip
2-Piece Fixing Ties With Pipe Clip,Cable Tie With Cable Clip,Cable Tie Clip,Clip On Tie Clips
Wenzhou Langrun Electric Co.,Ltd , https://www.langrunele.com