
Talking about the basic principles of Capsule Network
Half a month ago, Hinton’s long-awaited Dynamic Routing Between Capsules was finally made public on arixv. The first author was Sara Sabour. According to Hinton himself, Sabour was an Iranian who wanted to go to Washington University to read computer vision. But the visa was rejected by the United States, so Google’s Toronto Artificial Intelligence Lab dug her up and followed Hinton’s research on the Capsule Network.
Dynamic Routing Between CapsulesMatrix Capsules with EM RoutingFirst, let's talk about why Hinton proposes Capsule Network. Traditional image recognition is done using CNN (as shown in the figure below). CNN is usually composed of convolution layer and pooling layer. Convolution layer extracts each image from original image. For local features, the pooling layer is responsible for summarizing the local features, and the final model outputs the probability distribution of each category through the softmax classifier.
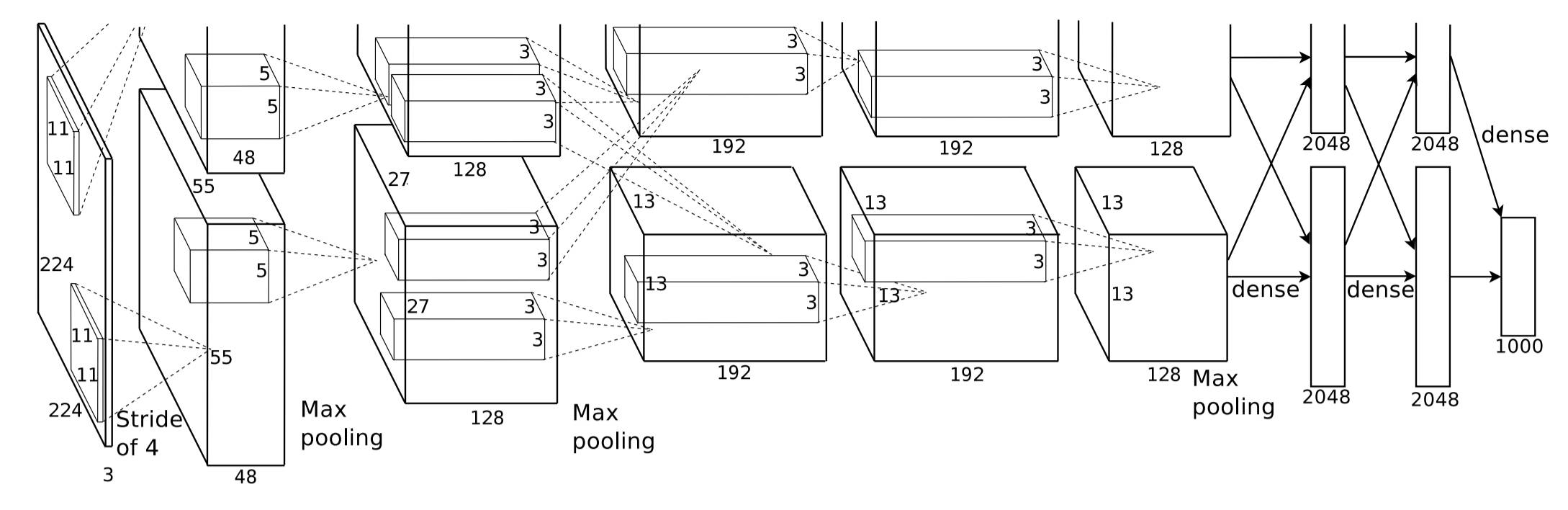
CNN seems to be very reasonable for image recognition, and the actual performance is very good, but Hinton thinks that the pooling operation in CNN is a disaster. The reason is that the pooling operation can only give rough location information, allowing the model to be somewhat The small spatial changes turn a blind eye and do not accurately learn the positional associations of different objects, such as the position, size, direction, and even the degree of deformation and texture of an entity within an area. Although CNN can recognize a normal face, if you reverse the position of one eye in the face photo with the mouth, CNN will still recognize the adult face, which is wrong. Although the purpose of pooling is to maintain the invariance of the position and direction of the entity, the simple and ruthless pooling operation of the largest or average in the actual situation will make the pooling effect counterproductive.
Human recognition pictures are based on translation and rotation to match the pictures you see to the patterns already in the brain. For example, for a statue, no matter what angle you take the picture, people can easily recognize that it is a statue, but this is for For CNN, it is very difficult. In order to solve this problem, that is, to better represent the various spatial attribute information of the entity, Hinton introduced the concept of Capsule Network in this article.
Each layer of Capsule Network is composed of many Capsules. A Capsule can output an activity vector. This vector represents the existence of an entity. The direction of the vector represents the attribute information of the entity. The length of the vector represents the probability of the existence of the entity. Therefore, even if the position or orientation of the entity changes in the picture, only the direction of the vector changes, and the length of the vector does not change, that is, the probability of existence of the entity does not change.
Unlike traditional neuron models, traditional neurons are mapped to another scalar by weighting the summation of each scalar and then mapping it to another scalar through a nonlinear activation function (such as sigmoid, tanh, etc.). Network is composed of a number of Capsules at each level, and its specific working principle can be divided into the following stages:
(1) The activity vector u_i generated by the lower-level Capsule is multiplied by a weight matrix W_ij to obtain the prediction vector u_ij_hat. The meaning of this vector is to predict the position of the high-dimensional feature according to the low-dimensional feature. For example, if Identifying a carriage, then a low-dimensional feature of a certain layer is a horse and a car, then the overall position of the carriage can be judged according to the horse, and the position of the carriage can also be judged according to the vehicle, if the judgment of the two low-dimensional features is If the position of the carriage is exactly the same, you can think of it as a carriage;
(2) If u is used to represent the output matrix of all Capsules of the previous layer, v is used to represent the output matrix of all Capsules of the next layer. It is known by (1) that the output vector u_i of each Capsule of the previous layer is calculated by weight. The prediction vector u_ij_hat, then it needs to pass this prediction vector to each Capsule of the next layer, but not to each Capsule of the next layer completely, but to multiply the coupling coefficient c_ij, This coupling coefficient can be considered to represent the degree of prediction of low-dimensional features on high-dimensional features. As for how the coupling coefficient c is determined, the iterative dynamic routing process will be described in detail later.
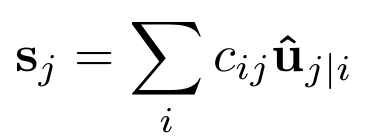
(3) Sum all the signals transmitted to the jth Capsule of the next layer, ie s_j=SUM(c_ij×u_ij_hat), which is similar to w*x in the neuron model, except that one is a scalar operation. The other is a vector operation;
(4) Similar to the activation function sigmoid in the neuron model, the input is mapped to the interval of 0 to 1. Here, the author uses a nonlinear squashing function to map the shorter vector to a vector whose length is close to 0, which will be longer. The vector is mapped into a vector whose length is close to 1, and the direction is always unchanged. This process is equivalent to normalizing the prediction vector. The resulting v_j is the output vector of the jth Capsule of the next layer.
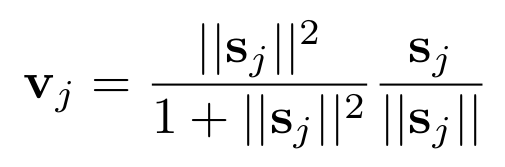
The above is the calculation flow of the activity vector of the Capsule between adjacent layers. Next, we will look at how the coupling vector c_ij between the Capsules of adjacent layers is determined.
First of all, we need to understand that since it is a weight, then for the Capsule i of the previous layer, the sum of all its c_ij must be equal to 1, and the number of c_ij is equal to the number of Capsules in the next layer. This c_ij is determined by the iterative dynamic routing algorithm. The core of the dynamic routing algorithm is to require the shallower Capsule activity vector to maintain a very high similarity with the higher layer Capsule activity vector.

As shown in the algorithm diagram above, b_ij in the second line is an unnormalized temporary cumulative variable with an initial value of 0, and its number is determined by the number of Capsules in the upper and lower layers. In each iteration, b is normalized by softmax to obtain a coefficient c_ij whose sum is 1 and the fifth row and the sixth row are forward-calculated and normalized by the squashing function to obtain the next layer. The output of the Capsule v_j, the seventh line is the core of the update c_ij (ie update b_ij), the new b_ij is equal to the old b_ij plus the "similarity" of the Capsule of the previous layer and the Capsule of the next layer. It can be seen from the figure that there is no convergence condition in this iterative process. The number of iterations is not given in detail in the paper. It is pointed out that the more iterations, the greater the probability of overfitting, the MNIST handwritten font. In the recognition experiment, the number of iterations set to 3 gives better performance.
The above has been said so much, only the definition algorithm of c_ij is explained. It seems that there is still a problem that has not been solved. Is that the value of other parameters determined? Back to the old method, the text still uses the backward propagation algorithm to update the parameter values, which involves the determination of the objective function. Taking MNIST handwritten digit recognition as an example, since the output category is 10, the number of Capsules can be set to 10 in the last layer. For each Capsule loss, it can be calculated according to the following formula. The total loss is 10 Capsules. The sum of the losses can be.

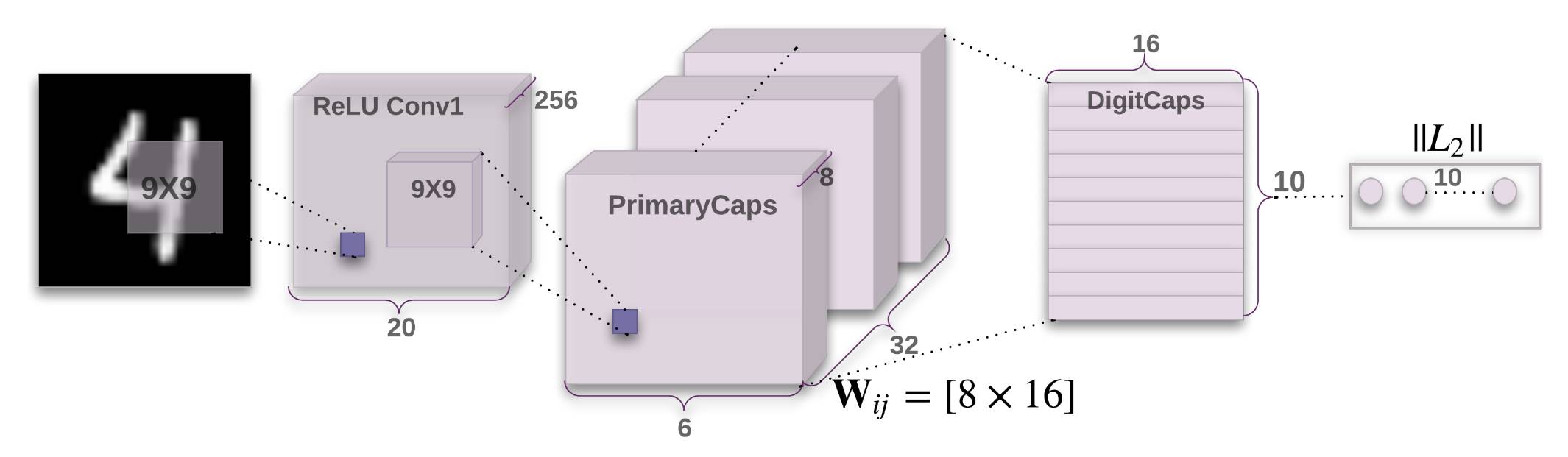
In addition to introducing the Capsule Network model, a Capsule Network based on convolutional neural network is designed for MNIST handwriting recognition. The following figure shows a simple three-layer Capsule Network. One picture first passes through a layer of CNN. (The convolution kernel size is 9×9, contains 256 feature maps, stride is set to 1, and the activation function is ReLU.) The local feature is used as the input of the primary Capsule. The primary Capsule is a convolutional layer containing 32 feature maps. The size of the product core is 9×9, stride is 2, and the number of convolutional neurons is 8, which means that there are 32×6×6 Capsules in this layer, and the dimension of the activity vector of each Capsule is 8. Each Capsule is in a 6x6 grid, they share their weights with each other, and the activation function used in the convolution is the squashing function described earlier. The last layer of DigitCaps is composed of 10 Capsules. The activity vector dimension of each Capsule is 16. The iterative dynamic routing algorithm needs to be executed between PrimaryCapsules and DigitCaps to determine the coupling coefficient c_ij. The whole process uses the Adam optimization algorithm to The parameters are updated.
Only a small data set MNIST is used as the evaluation of model performance, and the performance of Capsule Network is expected to be applied to larger machine learning tasks. The next few issues will continue to pay attention to the research progress of Capsule Network and its recognition in speech recognition. TensorFlow practice.
VOZOL BAR 2200 Vape are so convenient, portable, and small volume, you just need to take them
out of your pocket and take a puff, feel the cloud of smoke, and the fragrance of fruit surrounding you. It's so great.
We are China leading manufacturer and supplier of Disposable Vapes puff bars, vozol bar 2200 disposable vape,
vozol bar 2200 vape kit,vozol bar 2200 puffs vape, and e-cigarette kit, and we specialize in disposable vapes,
e-cigarette vape pens, e-cigarette kits, etc.
vozol bar 2200 disposable vape,vozol bar 2200 vape kit,vozol bar 2200 puffs vape,vozol bar 2200 vape pen,vozol bar 2200 e-cigarette
Ningbo Autrends International Trade Co.,Ltd. , https://www.supervapebar.com